리팩토링
REST API 설계 준수 : 기존 네이밍 규칙에 어긋나는 부분을 설계 원칙에 맞게 변경
- 예시: GET /report/clickheart?reportId={값} → GET /api/places/{placeId}/reports/{reportId}/heart
- 예시: POST /comment/enroll → POST /api/places/{id}/comment
ResponseEntity<ApiResponse<T>> 객체로 응답 형식 통일성 :
- ApiResponse (int status, String message, T data) 형식으로 응답 형식 통일
Global Exception Handler 예외 처리 :
- 커스텀 예외 객체를 생성하고 상황에 맞게 예외를 발생시켜 서버 오류 메시지 노출 최소화
무분별한 @Setter 방지를 통한 캡슐화 원칙 준수 :
- UPDATE 쿼리가 수행되는 필드에만 @Setter 설정
final 키워드와 생성자 Injection을 통한 싱글톤 빈 생성 :
- 객체 내부 필드 및 Spring Bean 간의 의존성 주입 불변성 보장
불필요한 @Transactional 제거 :
- 서비스 계층에서 조회 (SELECT 연산)에는 트랜잭션 오버헤드 제거
SOFT DELETE :
- ENUM을 활용하여 Status 필드로 물리적인 데이터는 유지하고, ENUM Status로 삭제 여부 판단
반정규화
가설 :
화장실 목록 필터링 시, 댓글 수(Count), 평균 별점(Average), 별점 개수(Count)의 정보가 필요하다.
위치가 변할 때 마다, 화장실 JOIN 댓글 JOIN 별점 및 GROUP BY 절이 수행되는 데,
데이터 크기가 늘어나면 조인 비용이 크게 증대될 것이다.
- Case 1 : 화장실 = 약 5000개, 별점 = 약 1000개, 댓글 = 약 1000개
- Case 2 : 화장실 = 약 5000개, 별점 = 약 30만개, 댓글 = 약 30만 개
- Case 3 : 화장실 = 약 5000개, 댓글수, 평균 별점, 별점 개수 칼럼 추가 후, JOIN 연산 없이 쿼리 수행
결과 정리 : 쓰레드가 DB커넥션 풀에 대기하지 않도록 쓰레드 당 30초 동안 총 쓰레드 30개 요청

결과 분석 :
예상대로 데이터 크기가 많은 Case2(30만개)에서 조인 비용 증가로 인해 성능이 좋지 않았다.
데이터 개수가 적은 경우에는 성능 상 차이가 거의 없었지만, 데이터 크기가 큰 경우 반정규화를 통해 API 요청시간이 평균601ms→14ms로 줄었다.
반면, Case1(1000개)에서 5000 * 1000 * 1000 조인 연산을 기대했으나,
조인 없는 Case3(반정규화)와 성능 차이가 거의 나지 않았다.
해당 쿼리에 대해 MYSQL DBMS 쿼리 수행 계획을 분석해보니
① 화장실 테이블에 where절로 필터링
② 화장실 JOIN 댓글 (Index Join)
③ (2번의 조인 결과) + 별점 테이블 (Hash Join) 순서로 DBMS가 쿼리 최적화를 해주었기 때문이다.
단점 : 댓글, 별점이 추가, 삭제될 때마다 반정규화된 칼럼을 업데이트하는 비용이 추가된다. 자칫 잘못하면 데이터 무결성이 깨진다.
인덱스
가설 :
현재 위치를 중심으로 1km 내의 위도와 경도 범위 조건으로 화장실 목록을 찾는 Range 쿼리가 매우 빈번히 수행되고,
테이블의 Full Scan이 필요한데, 인덱스를 활용하면 탐색 비용이 줄어들 것이다.
- Case 1 : 인덱스가 없는 경우
- Case 2 : 위도(lat)에만 인덱스 설정
- Case 3 : 단일 키 인덱스 2개 – 위도(lat), 경도(lng)
- Case 4 : 위도(lat), 경도(lng)에 합성 키 인덱스 설정
결과 정리 : 쓰레드가 DB 커넥션 풀에 대기하지 않도록 하여, 쓰레드 당 10초 동안 총 쓰레드 1000개 요청

결과 분석 :
화장실 목록은 조회가 매우 빈번하고, 데이터 수정과 삭제가 거의 없으므로 인덱스 갱신 비용이 거의 없다.
인덱스를 설정하기 적합한 조건이다.
위도와 경도 Range 쿼리에 대해 합성 키 인덱스를 설정하여 API 요청 시간이 평균 11ms → 4ms로 줄었다.
- Case 1 : 위도와 경도 조건으로 Full Scan이 일어난다.
- Case 2 : 위도(lat) 인덱스 상에서, 위도(lat) 조건만 일치하는 모든 테이블에 address 참조가 일어나서 비효율적이다.
- Case 3 : 각각 인덱스를 설정한 경우에 인덱스 스캔이 2번이 일어나서 비효율적일 것이라고 예상하였으나,
실제론 성능이 좋아졌다. Case 3에서 인덱스 스캔이 2번 일어나는 것이 순차적으로 실행되는 것이 아니라 병렬적으로 수행되기 때문이다. - Case 4 : 합성 키 인덱스를 활용하면 lat과 lng가 모두 일치하는 행에 대해서만 실제 테이블 address로 참조를 한다.
단점 : 인덱스 생성으로 인해 추가적으로 디스크 공간을 차지하며, 데이터 삽입 삭제 수정 시에 인덱스 테이블도 갱신 비용이 든다.
JPA N+1 문제
- @Query("SELECT c FROM Comment c join fetch c.member WHERE c.place.id = :id") – fetch join
- @Query("SELECT c FROM Comment c WHERE c.place.id = :id") – N+1
가설 :
특정 화장실에 댓글 목록을 가져올 때, 댓글의 작성자 이름을 가져와야 한다.
특정 화장실의 댓글 목록이 10개일 때, 작성자 이름을 조회하는 10개의 추가 쿼리가 발생한다.
데이터 개수가 적으면 FETCH JOIN을 사용하면 성능이 좋아지지만, 데이터 개수가 많으면 성능이 저하될 것이다.
- Case 1 : N+1 문제 발생, 테이블 당 데이터 1000개
- Case 2 : FETCH JOIN 사용, 테이블 당 데이터 1000개
- Case 3 : N+1 문제 발생, 테이블 당 데이터 약 30만 개
- Case 4 : FETCH JOIN 사용, 테이블 당 데이터 약 30만 개
결과 정리 : 쓰레드가 DB 커넥션 풀에 대기하지 않도록 하여, 쓰레드 당 10초 동안 총 쓰레드 100개 요청

결과 분석 :
데이터 개수가 적을 때, Case 1과 비교해서 Case 2에서 FETCH JOIN을 통해 작성자 목록을 한 번에 가져오니,
예상대로 API 요청 시간이 평균 10ms → 6ms로 줄었다.
Case 3과 비교해서 Case 4에서
예상과 달리, 여전히 FETCH JOIN이 평균 11ms → 7ms로 더 우수한 성능을 보여주었다.
① WHERE 절에 화장실 ID로 10개의 댓글이 필터링
② 댓글 테이블 [외래 키 작성자 ID]로 작성자 테이블에 인덱스 스캔 [조인 연산]
데이터 개수가 많아도 조인 최적화로 여전히 빠른 검색 성능을 보여준다.
Case 4에서는 1번의 인덱스 스캔으로 작성자 ID 10개를 찾고,
Case 3에서는 10번의 인덱스 스캔으로 작성자 ID 10개를 찾기 때문이다.
추가 검증 : 다소 과장해서, 특정 화장실 댓글이 10000개이고, 모두 동일한 작성자이면 결과는 어떻게 될까?
- Case 5 : 동일한 작성자 댓글 10000개, N+1 문제 발생, 테이블 당 데이터 약 30만 개
- Case 6 : 동일한 작성자 댓글 10000개, FETCH JOIN 사용, 테이블 당 데이터 약 30만 개
추가 검증 정리 : 쓰레드가 DB 커넥션 풀에 대기하지 않도록 하여, 30초 동안 총 쓰레드 30개 요청

추가 검증 분석 :
- Case 5 : 특정 화장실 댓글 목록 조회 쿼리 1번과 해당 작성자 정보 쿼리 1번으로 총 2번(1+1)의 쿼리가 발생한다. JPA 영속 컨텍스트 1차 캐시에 해당 작성자 엔티티가 등록되기 때문이다.
- Case 6 : FETCH JOIN에서 JOIN 결과 테이블에는 1만 개의 댓글에 해당 작성자 정보가 1만 번 중복하여 생성된다.
객체 지향과 데이터베이스 테이블의 근본적인 패러다임 차이로 인해,
중복된 정보로 조인 테이블 생성하는 비용보다 조인 없이 쿼리를 1 → 2번 더 수행하는 비용이 오히려 더 낮아졌다.
트랜잭션 격리 수준
가설 : 별점을 등록하는 트랜잭션은 다음과 같이 수행된다.
데이터의 무결성을 유지하면서 최소한의 트랜잭션 격리 수준으로 설정하면 동시성을 보장하면서 성능을 향상시킬 수 있을 것이다.





SELECT FOR UPDARE 적용 후


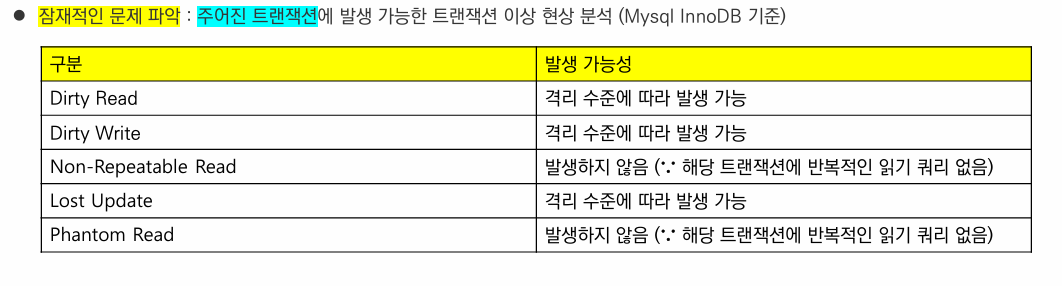
트랜잭션 이상 현상 정리 : 아래 표에 따라, 데이터 무결성을 유지하려면 5~7번 방식을 선택해야 한다.


MySQL InnoDB에서
일반 SELECT는 REPEATABLE READ 이상에서는 해당 트랜잭션의 언두 로드(Undo Log)에 기록된 최신 스냅샷을 참조한다.
SELECT FOR UPDATE는 언두 로그(Undo Log)에는 Lock을 걸 수 없어 스냅샷이 아닌 현재 레코드를 조회하고
READ COMMITTED - 레코드 락
REPEATABLE READ - Next Key 락(레코드 락 + Gap 락)이 걸린다.
Gap Lock을 통해서 팬텀 리드를 방지한다.
TPS 성능 (200 OK 기준) :

결과 분석 :
- 트랜잭션 격리 수준이 높을수록(↑), TPS는 떨어진다. (↓)
- 초당 Thread의 개수가 늘어날수록 (↑) , TPS는 떨어진다. (↓)
격리 수준이 높을수록 Lock으로 인한 오버헤드가 증가해 트랜잭션 처리 시간이 증가하고, Lock 획득 시간이 늘어나기 때문이다.
초당 Thread 개수가 늘어날수록 쓰레드 간의 Context Switch 시간이 증가하여 CPU 대기 시간이 늘어나고, 획득한 Lock을 계속 유지하기 때문이다.
Repeatable Read와 Read Committed 격리 수준에서 스냅샷 조회 방식이 서로 다르지만, Select For Update는 격리 수준과 상관없이 항상 DB에 조회하므로 두 격리 수준은 성능에 큰 차이가 나지 않았다.
결론 :
주어진 상황에 반복적인 Select 쿼리가 없으므로, Read Committed + 비관적 락이 데이터 무결성을 유지하면서 성능이 가장 좋았다. 따라서, Read Committed 격리 수준 + 비관적 락으로 설정하기로 하였다.
Dead Lock 발생 : 테스트에서 발생한 오류를 확인해보니, DeadLockLoserDataAccessException 이 발생하였다.

해결 방안 : 비관적 락을 화장실 테이블의 Version 칼럼을 활용하는 낙관적 락으로 바꾼다.

비관적 락 vs 낙관적 락 TPS 비교 : 비관적 락은 재시도 없음, 낙관적 락은 0.1초 후 재시도 최대 5회

최종 결론 정리 :
- READ UNCOMMITTED : 신뢰성이 없다.
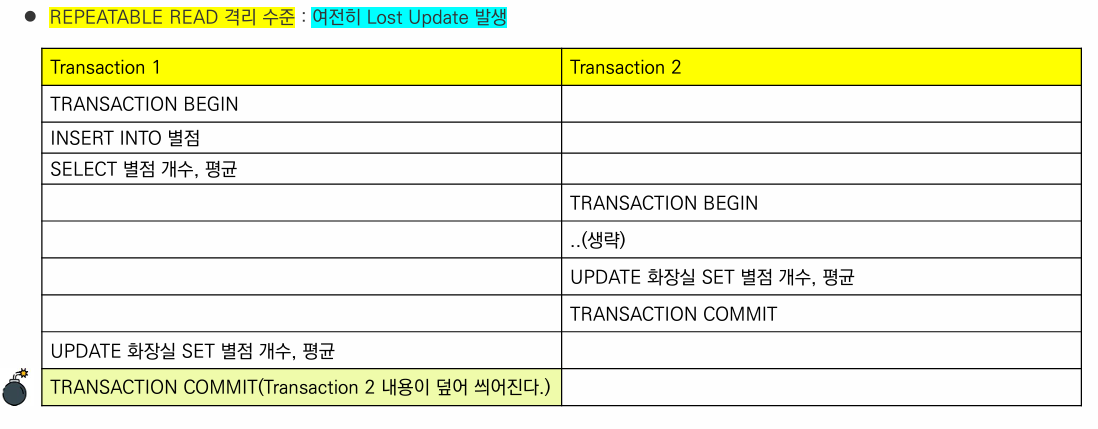
- READ COMMITTED : 반복적인 읽기가 없을 때 고려할 만하지만, Lost Update로 인해 추가적인 Lock이 필요할 수 있다.
- REPEATABLE READ : 반복적인 읽기가 있을 때 고려할 만하지만, Lost Update로 인해 추가적인 Lock이 필요할 수 있다.
- SERIALIZE : 성능은 떨어지지만, 개발자가 추가적인 Lock 설정 없이도 데이터 무결성은 확실하게 보장해준다.
- 낙관적 락 : Lock으로 인한 오버헤드가 없어, Thread 개수가 적을 때는 충돌 감지와 재시도가 성능을 향상시키지만,
Thread 개수가 많아지면 오히려 재시도로 인해 쓰레드가 소멸되지 않아 Context Switch 비용이 증가한다.
쓰레드 개수가 적당한 수준에서 효율적이다. - 비관적 락 : Lock으로 인한 오버헤드로, Thread 개수가 적을 때 성능이 좋지 않다.
Thread 개수가 많아지면, 재시도가 없기 때문에 즉시 DeadLockException이 발생되어, Context Switch 비용이 적다.